
1) joining more than 3 tables (Solution)
2) finding duplicate records from a table (Solution)
select COUNT(*),* from testDuplicateRds group by FirstName,LastName,Salary having COUNT(*)>1
3) second highest salary of employee using rownum (Solution)
select min(Salary) from (select distinct top 3 Salary,EmpName from Employee order by Salary desc) as emp
select top 1* from ( select RANK() over(order by Salary desc)as rn, Salary,EmpName from Employee ) as emp where rn=3
http://www.w3resource.com/sql-exercises/sql-subqueries-exercises.php
http://www.interviewquestionspdf.com/2014/08/ms-sql-server-trickycomplex-interview.html
http://www.bullraider.com/database/sql-tutorial/7-complex-queries-in-sql
http://www.complexsql.com/complex-sql-queries-examples-with-answers/
http://www.interviewquestionspdf.com/2014/07/sql-queries-interview-questions-answers.html
http://narendra86.blogspot.in/2013/10/top-80-sql-query-interview-questions.html
http://www.programmerinterview.com/index.php/database-sql/advanced-sql-interview-questions-continued-part-2/
1. Reverse a string without using REVERSE function. [reverse a string without using TSQL's REVERSE() function]
declare @str1 varchar(max) ='abcdui'
declare @len int= LEN(@str1)
declare @count int =LEN(@str1)
declare @str2 varchar(max)=''
--select SUBSTRING('abcdui',6,1)
while(@count>=1)
begin
set @str2=@str2+ SubString(@str1,@count,1)
select @str2;
set @count=@count-1;
end
select @str2
2. Generate hierarchy of Manager & Employee in Employee table with EmpID, EmpName, MgrID columns.
3. How do you sync rows in 2 tables, rows in first table being INSERTED/UPDATED/DELETED, and no modifications on the second table.
4. Generate Running total (sum) for goods sold by a Sales Rep for every day month wise for a given year (SalesRepID, Year, Month, Day, TotalSale).[Calculating Running Totals]
5. Get 5 Employees from every Department getting highest salary (EmpID, DeptID, Salary)
;with cte as
(select DENSE_RANK() over(PARTITION by DeptId order by Salary desc) r, DeptId,Salary from Employee E )
select distinct DeptId,Salary from cte where r in (1,2,3)
6. Get Employee with 2nd or nth highest salary [SQL Trivia - Find second (or nth) Highest Salary or Marks]
7. How to DELETE duplicate records from a table with a single SELECT stmt.[Identify & Delete Duplicate records from a table]
;with cte
as
(select ROW_NUMBER() over(partition by FirstName,lastname order by Salary ) rno ,* from testDuplicateRds )
delete from cte where rno>1
8. Allocate position to Students of a class based upon their marks, if same marks same position should be applied. [RANKING FUNCTIONS | ROW_NUMBER, RANK, DENSE_RANK, NTILE]
9. For these 2 tables: Product(ProductID, ProductName), Sales(SalesOrderID, ProductID, SaleDate)
- Get the list of Products that were sold last year.
- Get the list of Products that were NOT sold last year.
10. For any given date, get the Last Date of: Previous Month & Current Month & Next Month.
11. Difference Between:
- WHERE, GROUP BY and HAVING clause
- EXECUTE (or EXEC) vs sp_executesql
- ISNULL vs COALESCE
- PIVOT and UNPIVOT
- TRUNCATE, DELETE and DROP
- Stored Procedures vs Functions
- UNION ALL vs UNION
- Temporary Tables vs Table Variables
- THROW vs RAISERROR
- NOLOCK and READPAST table hints
- Decimal and Numeric datatypes
- Clustered vs NonClustered Indexes
- CURSORS vs WHILE loops
- CROSS APPLY vs OUTER APPLY operators
- Scalar, Table Valued (ITV), MultiSelect (MTV) - UDFs (User Defined Functions)
https://www.quora.com/What-are-the-frequently-asked-basic-and-complex-queries-SQL-during-a-tech-interview
INTRODUCTION
SQL queries most asked in .NET/SQL Server job interviews. These tricky queries may be required in your day to day database usage.BACKGROUND
This article demonstrates some commonly asked SQL queries in a job interview. I will be covering some of the common but tricky queries like:-
(i) Finding the nth highest salary of an employee.
(ii) Finding TOP X records from each group.
(iii) Deleting duplicate rows from a table.
NOTE : All the SQL mentioned in this article has been tested under SQL Server 2005. (ii) Finding TOP X records from each group.
(iii) Deleting duplicate rows from a table.
(i) Finding the nth highest salary of an employee.
Create a table named Employee_Test and insert some test data as:-
Hide Copy Code
CREATE TABLE Employee_Test ( Emp_ID INT Identity, Emp_name Varchar(100), Emp_Sal Decimal (10,2) ) INSERT INTO Employee_Test VALUES ('Anees',1000); INSERT INTO Employee_Test VALUES ('Rick',1200); INSERT INTO Employee_Test VALUES ('John',1100); INSERT INTO Employee_Test VALUES ('Stephen',1300); INSERT INTO Employee_Test VALUES ('Maria',1400);It is very easy to find the highest salary as:-
Hide Copy Code
--Highest Salary select max(Emp_Sal) from Employee_TestNow, if you are asked to find the 3rd highest salary, then the query is as:-
Hide Copy Code
--3rd Highest Salary select min(Emp_Sal) from Employee_Test where Emp_Sal in (select distinct top 3 Emp_Sal from Employee_Test order by Emp_Sal desc)The result is as :- 1200
To find the nth highest salary, replace the top 3 with top n (n being an integer 1,2,3 etc.)
Hide Copy Code
--nth Highest Salary select min(Emp_Sal) from Employee_Test where Emp_Sal in (select distinct top n Emp_Sal from Employee_Test order by Emp_Sal desc)
(ii) Finding TOP X records from each group
Create a table named photo_test and insert some test data as :-
Hide Copy Code
create table photo_test ( pgm_main_Category_id int, pgm_sub_category_id int, file_path varchar(MAX) ) insert into photo_test values (17,15,'photo/bb1.jpg'); insert into photo_test values(17,16,'photo/cricket1.jpg'); insert into photo_test values(17,17,'photo/base1.jpg'); insert into photo_test values(18,18,'photo/forest1.jpg'); insert into photo_test values(18,19,'photo/tree1.jpg'); insert into photo_test values(18,20,'photo/flower1.jpg'); insert into photo_test values(19,21,'photo/laptop1.jpg'); insert into photo_test values(19,22,'photo/camer1.jpg'); insert into photo_test values(19,23,'photo/cybermbl1.jpg'); insert into photo_test values (17,24,'photo/F1.jpg');There are three groups of pgm_main_category_id each with a value of 17 (group 17 has four records),18 (group 18 has three records) and 19 (group 19 has three records).
Now, if you want to select top 2 records from each group, the query is as follows:-
Hide Copy Code
select pgm_main_category_id,pgm_sub_category_id,file_path from ( select pgm_main_category_id,pgm_sub_category_id,file_path, rank() over (partition by pgm_main_category_id order by pgm_sub_category_id asc) as rankid from photo_test ) photo_test where rankid < 3 -- replace 3 by any number 2,3 etc for top2 or top3. order by pgm_main_category_id,pgm_sub_category_idThe result is as:-
Hide Copy Code
pgm_main_category_id pgm_sub_category_id file_path 17 15 photo/bb1.jpg 17 16 photo/cricket1.jpg 18 18 photo/forest1.jpg 18 19 photo/tree1.jpg 19 21 photo/laptop1.jpg 19 22 photocamer1.jpg
(iii) Deleting duplicate rows from a table
A table with a primary key doesn’t contain duplicates. But if due to some reason, the keys have to be disabled or when importing data from other sources, duplicates come up in the table data, it is often needed to get rid of such duplicates.This can be achieved in tow ways :-
(a) Using a temporary table.
(b) Without using a temporary table.
(a) Using a temporary or staging table
Let the table employee_test1 contain some duplicate data like:-
Hide Copy Code
CREATE TABLE Employee_Test1 ( Emp_ID INT, Emp_name Varchar(100), Emp_Sal Decimal (10,2) ) INSERT INTO Employee_Test1 VALUES (1,'Anees',1000); INSERT INTO Employee_Test1 VALUES (2,'Rick',1200); INSERT INTO Employee_Test1 VALUES (3,'John',1100); INSERT INTO Employee_Test1 VALUES (4,'Stephen',1300); INSERT INTO Employee_Test1 VALUES (5,'Maria',1400); INSERT INTO Employee_Test1 VALUES (6,'Tim',1150); INSERT INTO Employee_Test1 VALUES (6,'Tim',1150);Step 1: Create a temporary table from the main table as:-
Hide Copy Code
select top 0* into employee_test1_temp from employee_test1Step2 : Insert the result of the GROUP BY query into the temporary table as:-
Hide Copy Code
insert into employee_test1_temp select Emp_ID,Emp_name,Emp_Sal from employee_test1 group by Emp_ID,Emp_name,Emp_SalStep3: Truncate the original table as:-
Hide Copy Code
truncate table employee_test1Step4: Fill the original table with the rows of the temporary table as:-
Hide Copy Code
insert into employee_test1 select * from employee_test1_tempNow, the duplicate rows from the main table have been removed.
Hide Copy Code
select * from employee_test1gives the result as:-
Hide Copy Code
Emp_ID Emp_name Emp_Sal 1 Anees 1000 2 Rick 1200 3 John 1100 4 Stephen 1300 5 Maria 1400 6 Tim 1150
(b) Without using a temporary table
Hide Copy Code
;with T as ( select * , row_number() over (partition by Emp_ID order by Emp_ID) as rank from employee_test1 ) delete from T where rank > 1The result is as:-
Hide Copy Code
Emp_ID Emp_name Emp_Sal 1 Anees 1000 2 Rick 1200 3 John 1100 4 Stephen 1300 5 Maria 1400 6 Tim 1150
What does UNION do? What is the difference between UNION and UNION ALL?
List and explain the different types of JOIN clauses supported in ANSI-standard SQL.
Consider the following two query results:
SELECT count(*) AS total FROM orders;
+-------+
| total |
+-------+
| 100 |
+-------+
SELECT count(*) AS cust_123_total FROM orders WHERE customer_id = '123';
+----------------+
| cust_123_total |
+----------------+
| 15 |
+----------------+
Given the above query results, what will be the result of the query below?
SELECT count(*) AS cust_not_123_total FROM orders WHERE customer_id <> '123'
Find top SQL talent today. Toptal can match you with the best developers to finish your project.
HIRE TOPTAL’S SQL DEVELOPERS
What will be the result of the query below? Explain your answer and provide a version that behaves correctly.
select case when null = null then 'Yup' else 'Nope' end as Result;
Given the following tables:
sql> SELECT * FROM runners;
+----+--------------+
| id | name |
+----+--------------+
| 1 | John Doe |
| 2 | Jane Doe |
| 3 | Alice Jones |
| 4 | Bobby Louis |
| 5 | Lisa Romero |
+----+--------------+
sql> SELECT * FROM races;
+----+----------------+-----------+
| id | event | winner_id |
+----+----------------+-----------+
| 1 | 100 meter dash | 2 |
| 2 | 500 meter dash | 3 |
| 3 | cross-country | 2 |
| 4 | triathalon | NULL |
+----+----------------+-----------+
What will be the result of the query below?
SELECT * FROM runners WHERE id NOT IN (SELECT winner_id FROM races)
Explain your answer and also provide an alternative version of this query that will avoid the issue that it exposes.
Given two tables created and populated as follows:
CREATE TABLE dbo.envelope(id int, user_id int);
CREATE TABLE dbo.docs(idnum int, pageseq int, doctext varchar(100));
INSERT INTO dbo.envelope VALUES
(1,1),
(2,2),
(3,3);
INSERT INTO dbo.docs(idnum,pageseq) VALUES
(1,5),
(2,6),
(null,0);
What will the result be from the following query:
UPDATE docs SET doctext=pageseq FROM docs INNER JOIN envelope ON envelope.id=docs.idnum
WHERE EXISTS (
SELECT 1 FROM dbo.docs
WHERE id=envelope.id
);
Explain your answer.
What is wrong with this SQL query? Correct it so it executes properly.
SELECT Id, YEAR(BillingDate) AS BillingYear
FROM Invoices
WHERE BillingYear >= 2010;
Given these contents of the Customers table:
Id Name ReferredBy
1 John Doe NULL
2 Jane Smith NULL
3 Anne Jenkins 2
4 Eric Branford NULL
5 Pat Richards 1
6 Alice Barnes 2
Here is a query written to return the list of customers not referred by Jane Smith:
SELECT Name FROM Customers WHERE ReferredBy <> 2;
What will be the result of the query? Why? What would be a better way to write it?
Considering the database schema displayed in the SQLServer-style diagram below, write a SQL query to return a list of all the invoices. For each invoice, show the Invoice ID, the billing date, the customer’s name, and the name of the customer who referred that customer (if any). The list should be ordered by billing date.
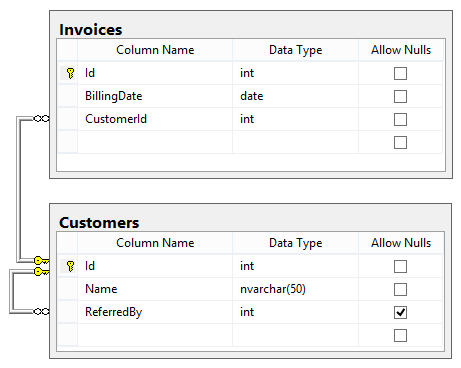 Assume a schema of
Assume a schema of Emp ( Id, Name, DeptId ) , Dept ( Id, Name).
If there are 10 records in the Emp table and 5 records in the Dept table, how many rows will be displayed in the result of the following SQL query:
Select * From Emp, Dept
Explain your answer.
Given a table SALARIES, such as the one below, that has m = male and f = femalevalues. Swap all f and m values (i.e., change all f values to m and vice versa) with a single update query and no intermediate temp table.
Id Name Sex Salary
1 A m 2500
2 B f 1500
3 C m 5500
4 D f 500
Given two tables created as follows
create table test_a(id numeric);
create table test_b(id numeric);
insert into test_a(id) values
(10),
(20),
(30),
(40),
(50);
insert into test_b(id) values
(10),
(30),
(50);
Write a query to fetch values in table test_a that are and not in test_b without using the NOT keyword.
Given a table TBL with a field Nmbr that has rows with the following values:
1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1
Write a query to add 2 where Nmbr is 0 and add 3 where Nmbr is 1.
Write a SQL query to find the 10th highest employee salary from an Employee table. Explain your answer.
(Note: You may assume that there are at least 10 records in the Employee table.)
Write a SQL query using UNION ALL (not UNION) that uses the WHERE clause to eliminate duplicates. Why might you want to do this?
Given the following tables:
SELECT * FROM users;
user_id username
1 John Doe
2 Jane Don
3 Alice Jones
4 Lisa Romero
SELECT * FROM training_details;
user_training_id user_id training_id training_date
1 1 1 "2015-08-02"
2 2 1 "2015-08-03"
3 3 2 "2015-08-02"
4 4 2 "2015-08-04"
5 2 2 "2015-08-03"
6 1 1 "2015-08-02"
7 3 2 "2015-08-04"
8 4 3 "2015-08-03"
9 1 4 "2015-08-03"
10 3 1 "2015-08-02"
11 4 2 "2015-08-04"
12 3 2 "2015-08-02"
13 1 1 "2015-08-02"
14 4 3 "2015-08-03"
Write a query to to get the list of users who took the a training lesson more than once in the same day, grouped by user and training lesson, each ordered from the most recent lesson date to oldest date.
What is an execution plan? When would you use it? How would you view the execution plan?
List and explain each of the ACID properties that collectively guarantee that database transactions are processed reliably.
What is a key difference between Truncate and Delete?
Given a table dbo.users where the column user_id is a unique identifier, how can you efficiently select the first 100 odd user_id values from the table?
(Assume the table contains well over 100 records with odd user_id values.)
How can you select all the even number records from a table? All the odd number records?
What are the NVL and the NVL2 functions in SQL? How do they differ?
What is the difference between the RANK() and DENSE_RANK() functions? Provide an example.
What is the difference between the WHERE and HAVING clauses?