
Introduction
Every C/C++ programmer worth his salt would have used a
struct one time or the other in his career. In C++, a struct is not very different from a class, except for the default accessibility of members. The situation is dramatically different in C#. This article attempts to introduce you gently to the differences between classes and structs in C#, and along the way, explains how to use structs correctly.Why we need structs
Java, a language similar to C# in many ways, does not have
structs, so what's the reason to add it to C#? The basic reason is the ability to create types with value semantics, which, if properly used, leads to better performance in a managed environment.
To substantiate, unlike Java, .NET supports the notion of value types and reference types (in Java, you can define only reference types). Instances of reference types get allocated in the managed heap and are garbage collected when there are no outstanding references to them. Instances of value types, on the other hand, are allocated in the stack, and hence allocated memory is reclaimed as soon as their scope ends. And of course, value types get passed by value (duh!), and reference types by reference. All C# primitive data types, except for
System.String, are value types.
In C#,
structs are value types, classes are reference types. There are two ways you can create value types, in C#, using the enum keyword and the struct keyword. Using a value type instead of a reference type will result in fewer objects on the managed heap, which results in lesser load on the garbage collector (GC), less frequent GC cycles, and consequently better performance. However, value types have their downsides too. Passing around a big struct is definitely costlier than passing a reference, that's one obvious problem. The other problem is the overhead associated with boxing/unboxing. In case you're wondering what boxing/unboxing mean, follow these links for a good explanation on boxing and unboxing. Apart from performance, there are times when you simply need types to have value semantics, which would be very difficult (or ugly) to implement if reference types are all you have.Classes and Structs
Here's a definition of a
struct in C#:
Hide Copy Code
public struct Foo
{
// Fields
private string fooString;
private int fooNumber;
// Property
public string FooString
{
get
{
return fooString;
}
set
{
fooString = value;
}
}
// Method
public int GetFooNumber()
{
return fooNumber;
}
}
As you can see, a
struct is very much like a class, but there are some important differences, let's look into them in more detail.1. Structs and Inheritance
structs derive from System.ValueType whereas classes derive from System.Object or one of its descendants. Of course, System.ValueType again derives from System.Object, but that's beside the point. structs cannot derive from any other class/struct, nor can they be derived from. However, a struct can implement any number of interfaces. Be aware, though, that when you treat the struct as an interface, it gets implicitly boxed, as interfaces operate only on reference types. So, if you do something like the following:
Hide Copy Code
struct Foo : IFoo
{
int x;
}
and then:
Hide Copy Code
IFoo iFoo = new Foo();
an instance of
Foo is created and boxed. All interface method calls then execute only on the boxed instance.2. Constructors
Although the CLR allows it, C# does not allow
structs to have a default parameterless constructor. The reason is that, for a value type, compilers by default neither generate a default constructor, nor do they generate a call to the default constructor. So, even if you happened to define a default constructor, it will not be called and that will only confuse you. To avoid such problems, the C# compiler disallows definition of a default constructor by the user. And because it doesn't generate a default constructor, you can't initialize fields when defining them, like:
Hide Copy Code
struct MyWrongFoo
{
int x = 1;
}
Remember, the compiler puts all this initialization code into the constructor (every constructor), and because there's no default constructor, you can't do the initialization.
Now, for the fun part.. You normally instantiate a
struct like this:
Hide Copy Code
Foo foo = new Foo();
As you had read earlier, even though you use the
new operator, the struct gets allocated on the stack. More interesting is the fact that you say new Foo() and yet there is no default constructor. The call new Foo() does not result in a call to the parameterless constructor, all it does is initialize the struct's fields to null/zero (using the .InitObj IL Opcode). As a proof, the following snippet will compile happily:
Hide Copy Code
struct Foo
{
int x;
public Foo(int x)
{
this.x = x;
}
}
class FooTester
{
[STAThread]
static void Main(string[] args)
{
Foo f = new Foo();
}
}
Note that I've defined an overloaded constructor and yet I'm able to call
new Foo(). This simply shouldn't be possible if the call to new resulted in a constructor call.
The only rule is that you need to initialize all fields of a
struct before using it. You can do that by:- calling
new Foo(). - calling an overloaded constructor. C# forces you to initialize all fields within every overloaded constructor, so there is no getting around the "initialize-everything" rule.
- explicitly setting every field's value. For e.g.:Hide Copy Code
Foo foo; foo.x = 0;
3. Destructors
You cannot define destructors (which are nothing but
Finalize methods) for structs. If you ever thought (like me) that using destructors and structs, you can get deterministic finalization, forget it! The compiler straightaway flags it as an error. Of course, structs can implement IDisposable (it being an interface), so you can always use the dispose pattern (albeit with the extra boxing overhead).4. Comparison against null
I know this is minor, but you can't compare an instance of a value type against
null. Things are changing with 2.0 though, with the introduction of "nullable types".. but that's material for another article!
5. The readonly keyword
For a reference type,
readonly prevents you from reassigning a reference to refer to some other object. It does not prevent you from changing the state of the referred object. For value types, however, readonly is like the const keyword in C++, it prevents you from changing the state of the object. This implies that you can't reassign it again, as that would result in reinitialization of all fields. The following piece of code demonstrates that.
Hide Shrink 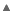 Copy Code
Copy Code
class MyReferenceType
{
int state;
public int State
{
get
{
return state;
}
set
{
state = value;
}
}
}
struct MyValueType
{
int state;
public int State
{
get
{
return state;
}
set
{
state = value;
}
}
}
class Program
{
readonly MyReferenceType myReferenceType = new MyReferenceType();
readonly MyValueType myValueType = new MyValueType();
public void SomeMethod()
{
myReferenceType = new MyReferenceType(); // Compiler Error
myReferenceType.State = 1234; // Ok
myValueType = new MyValueType(); // Compiler Error
myValueType.State = 1234; // Compiler Error
}
}
While it is the logical thing to do for value types, it can bite you in unexpected ways. Variables declared in
foreach statements and using statements are implicitly readonly, so if you are using structs there, you won't be able to change their states.When to use structs
So you've seen how
structs and classes differ. Here's when structs are better:- You want your type to look and feel like a primitive type.
- You create a lot of instances, use them briefly, and then drop them. For e.g., within a loop.
- The instances you create are not passed around a lot.
- You don't want to derive from other types or let others derive from your type.
- You want others to operate on a copy of your data (basically pass by value semantics).
Here's when not to use
structs:- The size of the
struct(the sum of the sizes of its members) gets large. The reason is that beyond a particular size, the overhead involved in passing it around gets prohibitive. Microsoft recommends that the size of astructshould ideally be below 16 bytes, but it really is up to you. In case yourstructhas reference types as members, make sure you don't include the size of instances of reference types, just the size of the references. - You create instances, put them in a collection, iterate and modify elements in the collection. This will result in a lot of boxing/unboxing as FCL Collections operate on
System.Object. Every addition will involve a boxing operation, and every modification will involve an unboxing followed by a boxing operation.
Conclusion
Some of the inefficiencies of using value types will go away with generics in C# 2.0, particularly when using collections, so things can only get better. It's great that C# allows you to choose how you want to implement your type, as a value or a reference type. Judicious use of value types can greatly increase application performance. Hopefully, this article will help you do that.
No comments:
Post a Comment