
Index Structures
Clustered Indexes
Nonclustered Indexes
Index Types
- Composite index: An index that contains more than one column. In both SQL Server 2005 and 2008, you can include up to 16 columns in an index, as long as the index doesn’t exceed the 900-byte limit. Both clustered and nonclustered indexes can be composite indexes.
- Unique Index: An index that ensures the uniqueness of each value in the indexed column. If the index is a composite, the uniqueness is enforced across the columns as a whole, not on the individual columns. For example, if you were to create an index on the FirstName and LastName columns in a table, the names together must be unique, but the individual names can be duplicated.
- Primary key: When you define a primary key constraint on one or more columns, SQL Server automatically creates a unique, clustered index if a clustered index does not already exist on the table or view. However, you can override the default behavior and define a unique, nonclustered index on the primary key.
- Unique: When you define a unique constraint, SQL Server automatically creates a unique, nonclustered index. You can specify that a unique clustered index be created if a clustered index does not already exist on the table.
- Covering index: A type of index that includes all the columns that are needed to process a particular query. For example, your query might retrieve the FirstName and LastName columns from a table, based on a value in the ContactID column. You can create a covering index that includes all three columns.
Index Design
Database
- For tables that are heavily updated, use as few columns as possible in the index, and don’t over-index the tables.
- If a table contains a lot of data but data modifications are low, use as many indexes as necessary to improve query performance. However, use indexes judiciously on small tables because the query engine might take longer to navigate the index than to perform a table scan.
- For clustered indexes, try to keep the length of the indexed columns as short as possible. Ideally, try to implement your clustered indexes on unique columns that do not permit null values. This is why the primary key is often used for the table’s clustered index, although query considerations should also be taken into account when determining which columns should participate in the clustered index.
- The uniqueness of values in a column affects index performance. In general, the more duplicate values you have in a column, the more poorly the index performs. On the other hand, the more unique each value, the better the performance. When possible, implement unique indexes.
- For composite indexes, take into consideration the order of the columns in the index definition. Columns that will be used in comparison expressions in the WHERE clause (such as WHERE FirstName = ‘Charlie’) should be listed first. Subsequent columns should be listed based on the uniqueness of their values, with the most unique listed first.
- You can also index computed columns if they meet certain requirements. For example, the expression used to generate the values must be deterministic (which means it always returns the same result for a specified set of inputs). For more details about indexing computed columns, see the topic “Creating Indexes on Computed Columns” in SQL Server Books Online.
Queries
- Try to insert or modify as many rows as possible in a single statement, rather than using multiple queries.
- Create nonclustered indexes on columns used frequently in your statement’s predicates and join conditions.
- Consider indexing columns used in exact-match queries.
Index Basics
SQL Server Indexes: Clustered Indexes
An Index in SQL Server is a data structure associated with tables and views that helps in faster retrieval of rows.
Data in a table is stored in rows in an unordered structure called Heap. If you have to fetch data from a table, the query optimizer has to scan the entire table to retrieve the required row(s). If a table has a large number of rows, then SQL Server will take a long time to retrieve the required rows. So, to speed up data retrieval, SQL Server has a special data structure called indexes.
An index is mostly created on one or more columns which are commonly used in the SELECT clause or WHERE clause.
There are two types of indexes in SQL Server:






Clustered Indexes
The clustered index defines the order in which the table data will be sorted and stored. As mentioned before, a table without indexes will be stored in an unordered structure. When you define a clustered index on a column, it will sort data based on that column values and store it. Thus, it helps in faster retrieval of the data.
There can be only one clustered index on a table because the data rows can be stored in only one order.
When you create a Primary Key constraint on a table, a unique clustered index is automatically created on the table.
As an example, create the following EmployeeDetails table that does not have a primary key.
CREATE TABLE dbo.EmployeeDetails(
EmployeeID int NOT NULL,
PassportNumber varchar(50) NULL,
ExpiryDate date NULL
)
Insert the following rows in the table.
Insert into EmployeeDetails values(3,'A5423215',null);
Insert into EmployeeDetails values(5,'A5423215',null);
Insert into EmployeeDetails values(2,'A5423215',null);
Insert into EmployeeDetails values(8,'A5423215',null);
Insert into EmployeeDetails values(1,'A5423215',null);
Insert into EmployeeDetails values(4,'A5423215',null);
Insert into EmployeeDetails values(6,'A5423215',null);
Insert into EmployeeDetails values(7,'A5423215',null);
The data in the EmployeeDetails table are not stored in any order. Execute the Select * from EmployeeDetails; and you will see the following result.
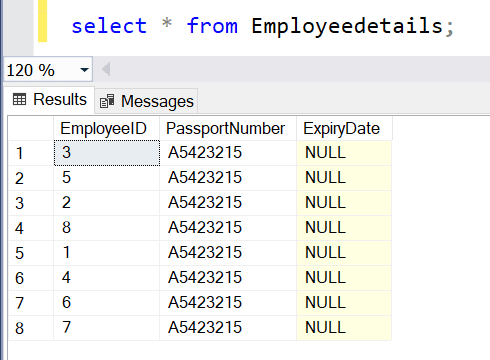
As you can see, the data is stored in the order in which they are inserted. Now, if you use the WHERE clause to filter out data, the query optimizer will scan the entire table rows to arrive at the required data. This is because the data is not in any order.
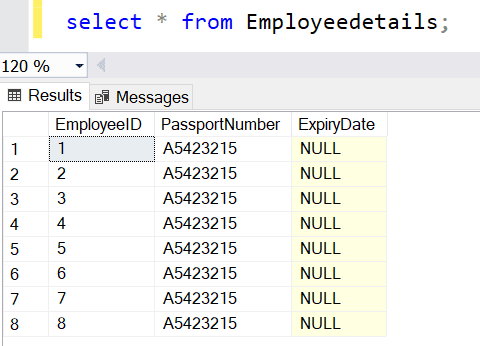
Create a clustered index on the EmployeeID column to sort and store the the data by EmployeeID. The data in the table will be sorted based on EmployeeID and executing the above query will return rows faster. This can be verified using SQL Server's execution plan.
Create Clustered Index Using T-SQL
The following is the syntax to create the clustered index on a table.
CREATE CLUSTERED INDEX <index_name>
ON [schema.]<table_name>(column_name [asc|desc]);
The following creates a clustered index on the EmployeeID column of the EmployeeDetails table.
CREATE CLUSTERED INDEX CIX_EmpDetails_EmpId
ON dbo.EmployeeDetails(EmployeeID)
The above statement will crean an index in the indexes folder, as shown below.
Now, Select * from EmployeeDetails; will return the following result.
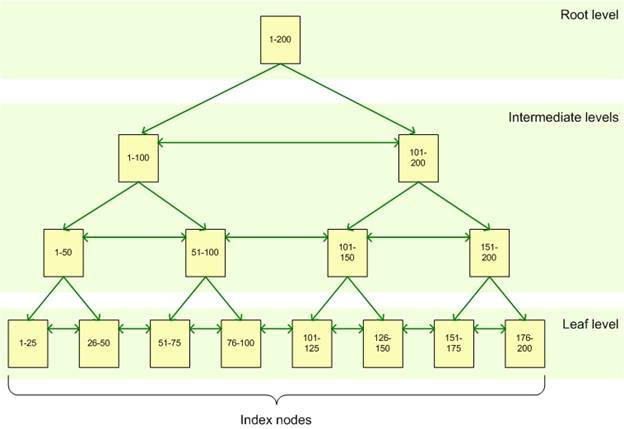
In a clustered index, the data is organized using a special structure called B-tree or a balanced tree structure. In B-tree, the top node is called the root node and the bottom nodes are called the leaf nodes. All index levels between the root and the leaf nodes are called intermediate levels. The leaf nodes contain the data pages. The root and intermediate levels contain index pages holding index rows and each index row contains a pointer either pointing to a data row in leaf node or to another intermediate level page. The pages in each level of the index are linked in a doubly linked list.
A clustered index can be created on two columns with different sorting order, as shown below.
CREATE CLUSTERED INDEX CIX_EmpDetails_EmpId
ON dbo.EmployeeDetails(EmployeeID ASC, PassportNumber DESC)
Create a Clustered index using SSMS
Step 1: Open SSMS and connect to the database. In the Object Explorer, expand the table where you want to create a clustered index.
Step 2: Right-click on the Indexes folder. Point to New Index and, select Clustered index.., as shown below.
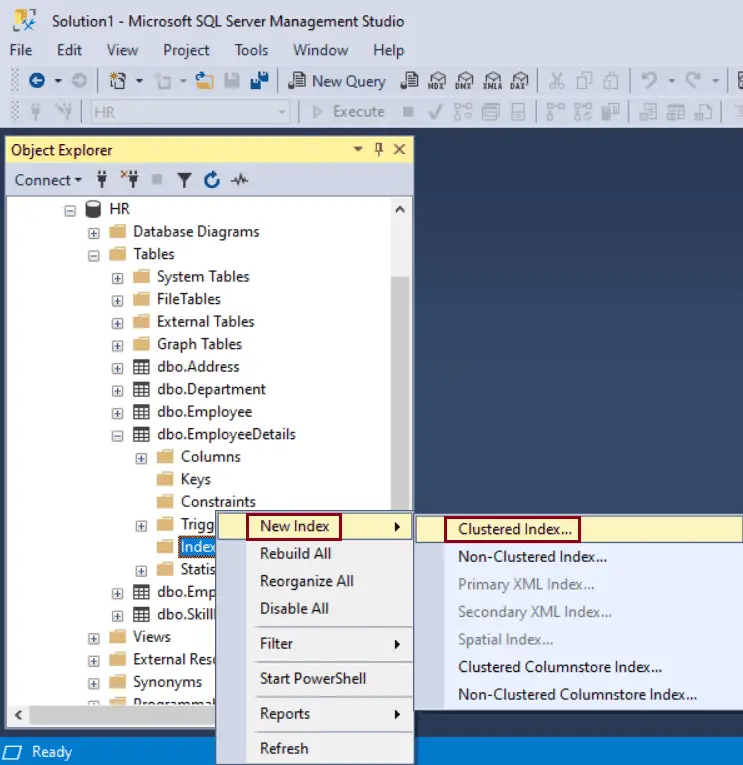
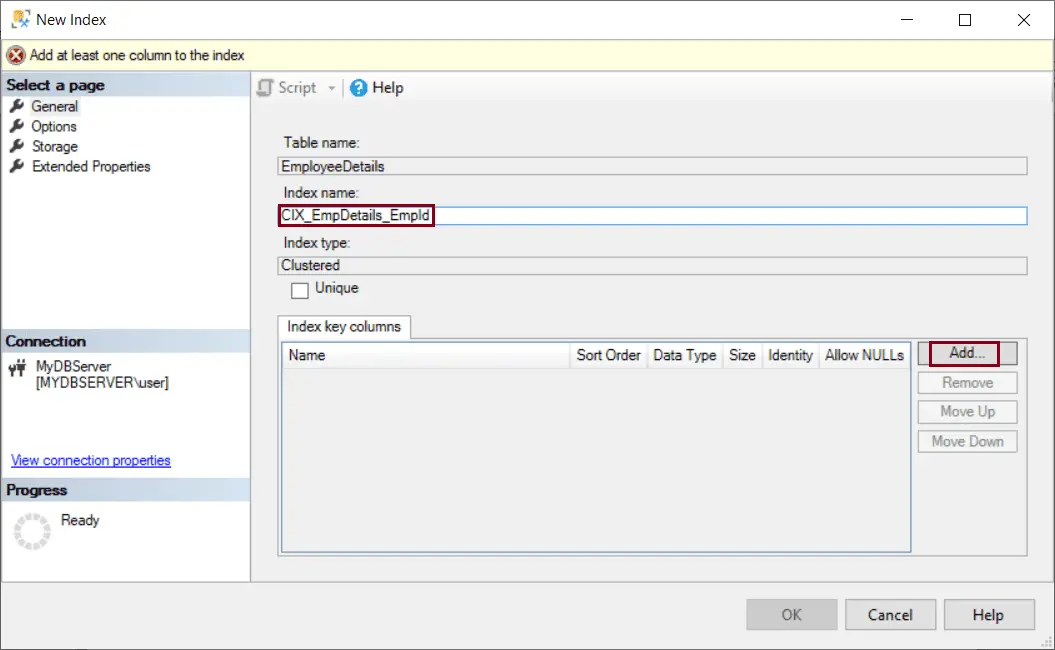
Step 3: In the New Index dialog box, on the General page, enter a name of an index under the Index Name and click on the Add button under the Index Key Columns, as shown below.
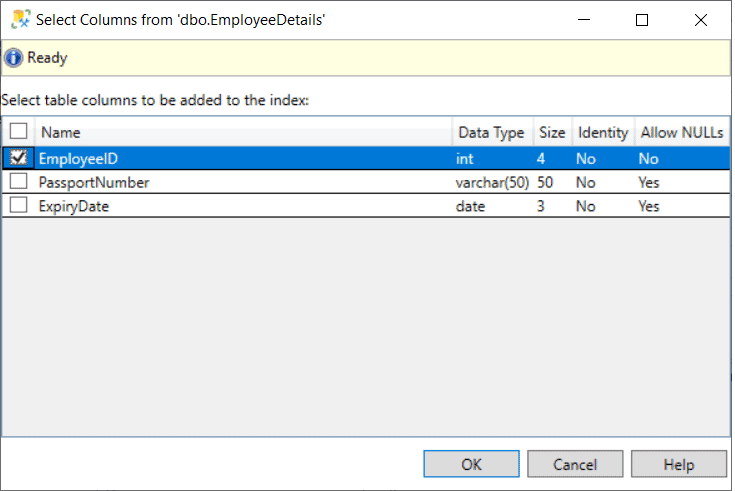
Step 5: In the Select Columns from table name dialog box, select the checkbox of the column(s) to be added to the clustered index.
Step 6: Click OK and save the table.
Create a Clustered Index using Table Designer
Another way to create a clustered index is by using the table designer in SSMS.
Step 1: In the Object Explorer, right-click on the table where you want to create a clustered index and click Design.
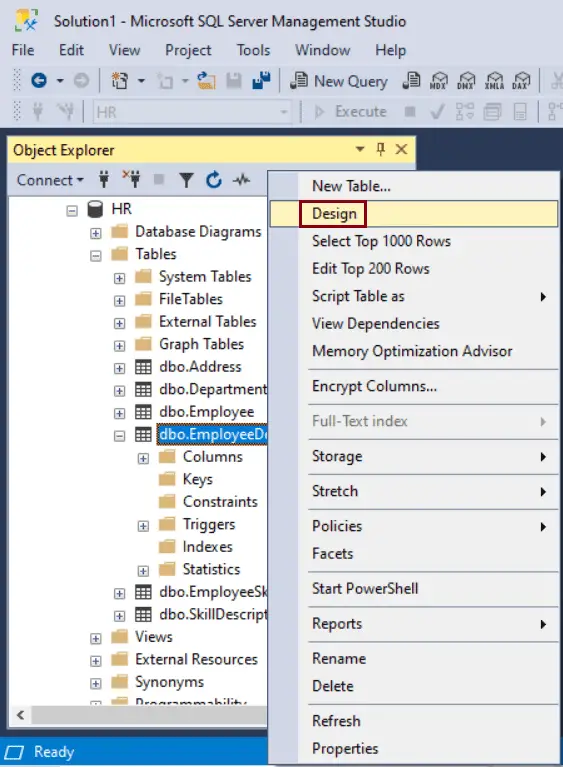
Step 2: On the Table Designer menu, click on Indexes/Keys.
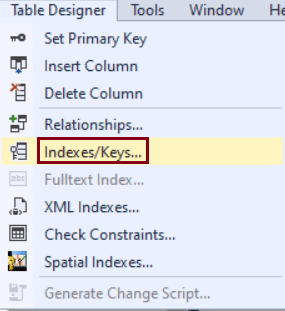
Step 3: In the Indexes/Keys dialog box, click on Add button.
Step 4: For the new Index created, select Yes from the dropdown list for Create as Clustered.
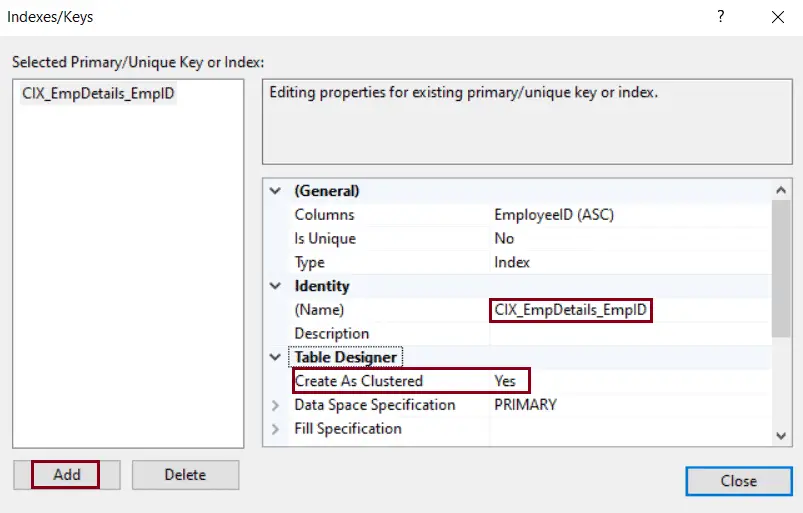
Step 5: Click close.
Step 6: Click Save table name from the File menu.
Learn how to create a non-clustered index in the next chapter.
Clustered Indexes without Primary key
The clustered index will still store the actual data pages at its leaf level, (initially) physically sorted by the name column.
The index navigation structure above the leaf level will contain the name column values for all rows.
So overall: nothing changes.
The primary key is a logical construct, designed to uniquely identify each row in your table. That's why it has to be unique and non-null.
The clustering index is a physical construct that will (initially) phyiscally sort your data by the clustering key and arrange the SQL Server pages accordingly.
While in SQL Server, the primary is used by default as the clustering key, the two do not have to fall together - nor does one have to exist with the other. You can have a table with a non-clustered primary key, or a clustered table without primary key. Both is possible. Whether it's sensible to have that is another discussion - but it's technically possible.
Update: if your primary key is your clustering key, uniqueness is guaranteed (since the primary key must be unique). If you're choosing some column that is not the primary key as your clustering key, and that column does not guarantee uniqueness, SQL Server will - behind the scenes - add a 4-byte (INT) uniqueifier column to those duplicates values to make them unique. So you might have Smith, Smith1, Smith2 and so forth in your clustered index navigation structure for your Smith's.
No comments:
Post a Comment